I recently found a relatively new library on github for handling categorical features named categorical_encoding and decided to give it a spin.
As a reminder – categorical features are variables in your data that have a finite (ideally small) set of possible values, for example months of the year or hair color. You can’t feed these into predictive models as raw text, so some conversion is necessary to prepare these variables to be useable. Typically, you create a new, separate column for each possible value (or alternately depending on the intended model, n-1 values) and each of these new columns acts as a true/false flag. This is called “One-Hot” encoding, and this is what we did in an earlier post for Titanic data variable transformations. There are other types of encodings as well that we’ll get to shortly.
There are plently of options for dealing with categorical data:
- Pandas has basic support for a “category” datatype, but that doesn’t save any work on the required transformations to prepare for modeling. No matter what datatype you’re dealing with, there is a method named get_dummies that will convert the unique values into separate columns.
- Scikit-learn has a few options for One-Hot encoding. First, there’s the appropriately named OneHotEncoder, but that only works if the values in the column are integers (doesn’t work if categories are strings, which they very often are). Additionally, scikit-learn it has the DictVectorizer object which performs One-Hot encoding for non-integer columns
- Categorical-Encoding is a user contributed library, and is what we’ll be going into more detail about. It handles One-Hot encoding like the others, but it also has some more exotic encodings for more complex use cases
Dummy vs. Contrast
Why do we need anything other than simple One-Hot/Dummy variables? Good news is – most of the time we don’t. Typically the only question to answer is whether or not to remove one of the dummy variables to improve performance. Whether this is the case depends on which model you’re using: certain types of regression, certain update algorithms for neural networks, Support Vector Machines, etc, do better if you use the full set of dummy variables rather than removing 1 dummy variable since it’s redundant. If you’re not sure which applies to your model just try it both ways and see if there is any difference.
Let’s say you want to get real hardcore with some linear models (I’m talking to you scientists) – this is the primary reason to use contrast encodings which is what the Category Encodings library provides in clear distinction to the built-in stuff from Pandas and scikit-learn. In it’s very simplest terms – “Contrast” encoding is a method by which you set the values of the columns for each distinct value in the categorical variable by means of a comparison to each of the other levels. So, rather than just setting one column to 1 and the others to 0, you may set all the columns to non-zero values, some are negative, some are positive, and the column values you use for each category value is calculated in a specific way. Each of the different encoding algorithms has a different approach for evaluating the “contrast” between the values. I’m going to spare you any more of my vague explanation of the details of what’s happening there. Instead I’ll point you to these links (the UCLA one is particularly good) which does a real bang-up job of explaining each of the calculations:
- http://www.ats.ucla.edu/stat/r/library/contrast_coding.htm
- http://psych.colorado.edu/~carey/Courses/PSYC5741/handouts/Coding%20Categorical%20Variables%202006-03-03.pdf
- http://statsmodels.sourceforge.net/devel/contrasts.html
- http://appliedpredictivemodeling.com/blog/2013/10/23/the-basics-of-encoding-categorical-data-for-predictive-models
Code
Let’s define a nice little imaginary test set:
df = pd.DataFrame({
'name': ['The Dude', 'Walter', 'Donny', 'The Stranger', 'Brandt', 'Bunny'],
'haircolor': ['brown', 'brown', 'brown', 'silver', 'blonde', 'blonde'],
'gender': ['male', 'male', 'male', 'male', 'male', 'female'],
'drink': ['caucasian', 'beer', 'beer', 'sasparilla', 'unknown', 'unknown'],
'age': [48, 49, 45, 63, 40, 23]
},
columns=['name', 'haircolor', 'gender', 'drink', 'age']
)
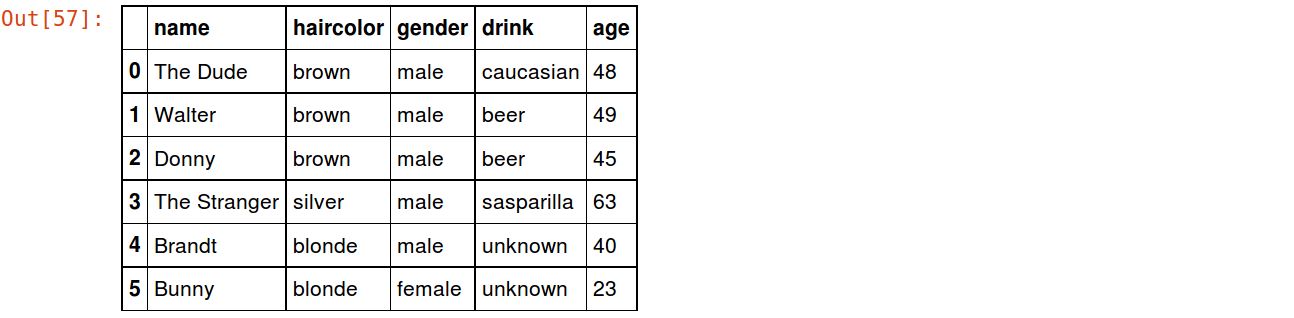
Let’s try the basic One-Hot encoding we’re all so familiar with:
encoder = ce.OneHotEncoder(cols=['haircolor']) df_onehot = encoder.fit_transform(df) df_onehot
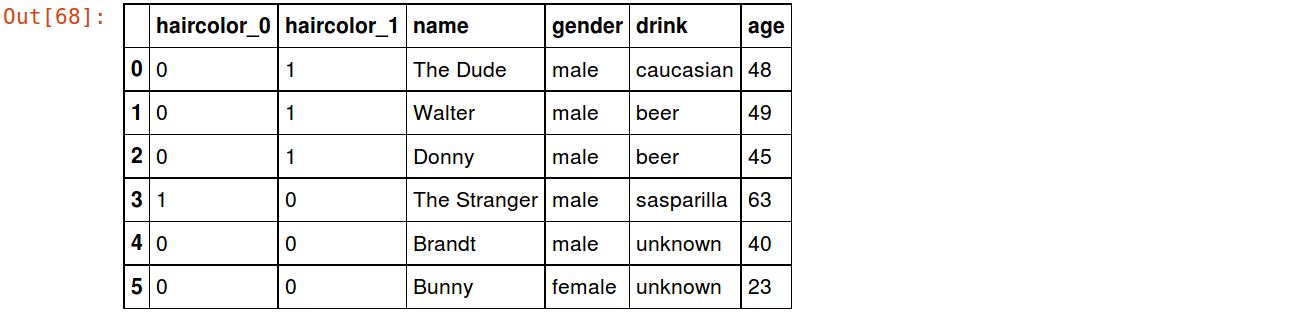
There’s another type of dummy encoding that can be used that is more space efficient than one-hot and often works as well or better – BinaryEncoding. This assigns a random number to each value, encodes the numbers as binary, and creates a column for as many bits are required to represent the binary versions of the number:
encoder = ce.BinaryEncoder(cols=['haircolor']) df_bina = encoder.fit_transform(df) df_bina
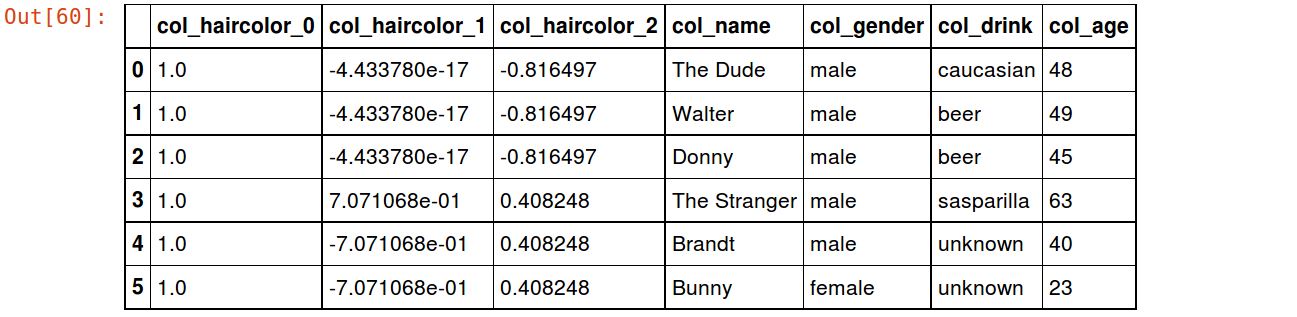
Now the Polynomial encoding which spits out some fun numbers:
encoder = ce.PolynomialEncoder(cols=['haircolor']) df_poly = encoder.fit_transform(df) df_poly
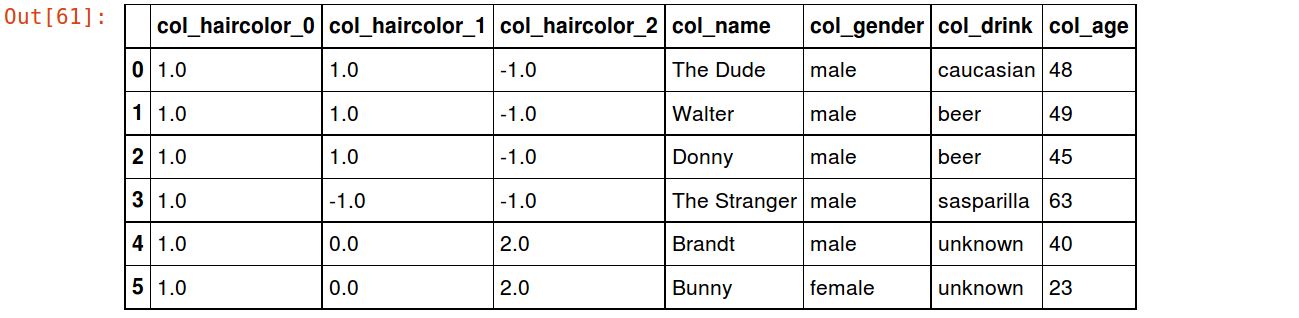
The HelmertEncoder (don’t know who Helmert is, don’t know why he made this, but for some reason it reminds me of “Dark Helmet” so it’s in):
encoder = ce.HelmertEncoder(cols=['haircolor']) df_helm = encoder.fit_transform(df) df_helm
There are a handful more, but that’s enough to get the idea. It’s entirely possible that you’ll complete a long, successful data science career without ever needing any of these specialized encoders, but it’s nice to know they’re there. Big shout out to Will McGinnis for putting this library together.
As usual, a full jupyter notebook containing all the code for this post is up on github: https://github.com/UltravioletAnalytics/blogcode/blob/master/category_encoders.ipynb